
Most baseball fans have a good handle on what type of hitter should in which spot in the batting order. For instance, a speedster should hit leadoff, your big slugger hitting cleanup, etc. Tom Tango, Mitchel Lichtman, and Andy Dolphin in their book “The Book” provided statistical analysis to optimize a batting order. They based their analyses on the number of plate appearances and the frequency of base/out states (e.g. how often the cleanup hitter comes to bat with runners in scoring position).
I won’t go through all the explanation as Tango, Lichtman, and Dolphin did a much better job. If you don’t want to read the original source, Beyond the Box Score did a great job providing an overview and Bluebird Banter went through some of the statistical analysis.
We wanted to see how that analysis would transfer to actual wins and losses. We looked at two scenarios using the greatest leadoff hitter, Rickey Henderson, and the greatest hitter of all-time, Babe Ruth.
As we normally do, we used OOTP16 and created 9 teams filled with average clone position players and pitchers. Then we imported the 1982 version of Rickey Henderson and cloned him to make nine Rickey’s – one for each team. For each team, he hit in a different spot in the batting order (including the ninth spot – there was no DH in this league so the pitcher batted eighth on that team).
Then we simmed almost 2000 games for each team, and (WARNING!!!! MATH TERM!!!) checked the binomial probability of each winning percentage to see if it was significantly different than what you might see flipping a coin 2000 times.
Here are the winning percentages for when Rickey hit in each spot in the lineup and the result of the binomial distribution calculation:
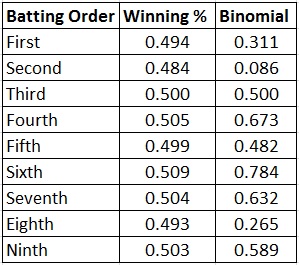
All values were not significantly different from a coin flip (a value of less than .050 would have meant they lost more significantly more games and a value greater than .950 would have meant they won significantly more games).
Surprisingly, the second spot in the batting order was the closest to being significant – but in the opposite way than expected, with the team losing more games than they won when Rickey hit second. The team performed the best when Rickey hit sixth.
So after almost 2000 games (more than 12 full seasons), it didn’t significantly matter where Rickey batted in the lineup. Each team’s win total was no different than what you might expect from flipping a coin 2000 times.
We did the same for Babe Ruth, using the 1921 version of Ruth that won our League of All-Time Greats. With Ruth, we found different results.
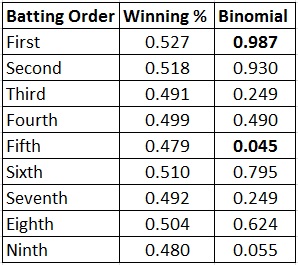
Hitting Ruth leadoff resulted in a significantly greater number of wins than expected by chance, due to the number of additional plate appearances by the leadoff hitter (4.66 PA/game as a leadoff hitter compared to 4.46 in the #2 spot, decreasing steadily down to 3.81 in the #9 hole).
Hitting Ruth second approached but did not meet the criteria for significance, while hitting Ruth 9th approached but did not reach significance for fewer wins than by chance. Surprisingly, hitting Ruth 5th did result in significantly fewer wins than expected over the course of almost 2000 games. We have no explanation for this, as Tango’s analysis says the number of plate appearances and the expected baserunner/out situations has the #5 spot as the fourth most important (after #1, 2, and 4).
Ruth’s RBI stats would have likely suffered by hitting him leadoff – in 12+ seasons he had 7% fewer RBIs than the Babe Ruth who hit 3rd and 18% fewer RBIs than the one who hit 4th – but the extra plate appearances would have likely led to marginally more home runs (4% more in our sim), and his relatively high on-base percentage would have had him on more for later hitters to bring in (the leadoff Ruth had 15% more runs).
Most importantly hitting him in the leadoff spot might have meant even more wins for the Yankees.
You can follow us on Twitter @BullpenByComm
“As we normally do, we used OOTP16 and created 9 teams filled with average clone position players and pitchers. ”
I am not clear on this. Does this mean the other 8 guys (not Ruth or Henderson) were identical statistically? Or does it mean that the 2B man on each team had the stats of an average hitting 2B man? (which would be a weak hitter, relatively)
Was the 1B man on each team a pretty good hitter? If so, in what lineup slot was each guy batting?
Hi Cyril, thanks for checking us out. What I meant was that all other players had the same ratings and all ratings were set to be average, so it didn’t matter where any of the other positions were in the lineup.
Okay, thanks.
But most teams have guys with varying OBPs and SLGs.
Have you done a simulation on the 1921 Yankees or 1982 A’s? That is, take the data for each actual hitter on those teams and see what works best for that team instead of putting Ruth or Henderson on a team where the 8 other guys are identical
Not yet, but I think that’s a great idea for a follow-up post. 🙂 Thanks!
I look forward to whatever you find
2000 games is nothing close to the point where you will learn anything. Start at 100,000 games.
On top of which, you don’t have to look at win%, just runs per 27 outs. To ensure that, always make the team bat on the road.
The range is runs per game from best to worst is going to be at most 0.15 runs per game. If you are getting more than say 0.20 runs per game, then you haven’t run enough simulations.
Hi Tom! Thanks for the work you have done, for checking us out, and of course for your feedback. I agree that more games is certainly better, but unfortunately I do this in my spare time so I have to make do with what there is time to do. However, I would look at the differentiation between a significant difference and a meaningful one. If during the course of a particular player’s career (since we did 12+ seasons’ worth of games which would typically be a really good career) we can’t find significance for something, then would any difference in going out to 100000 games be really meaningful?
When it comes to looking at R/27, I frequently get into similar discussions along these lines in my real job. R/27 is a surrogate measure to predict wins. A win is the ultimate goal of every game, so if we have a way to measure wins then what does a surrogate provide other than an imperfect (but excellent) prediction of what I’m already measuring?
Even if wins is what we are after, going from runs to wins as you are doing adds a huge level of random variation. And with only 2000 games, you won’t find any significance in your results.
Just because you don’t find significance in 200 or 2000 or 20,000 games does NOT mean you won’t find the same in 200,000 and 2 million games. The more games you have the more significance you will find, in absolutely EVERYTHING that is not random. And moving players around is NOT random.
If you aren’t finding significance for EVERY lineup slot, that means you didn’t run enough simulations. The needle is definitely in the haystack.
I completely agree that you will find significance in everything that is not random. I guess my point is the distinction between something that is statistically significant and something that is statistically meaningful. Yes, I can find that needle in a haystack if I look hard enough, but if that needle is contributing so little to the variation we see that it takes simming 2 million games to find it, I would question whether it’s meaningful enough to justify digging for it. It would be time better spent to look at larger contributing factors to the variation.
If differences are so small that simming an entire career can’t make a variable break out of the noise (which it did with Ruth but not with Rickey) then I’d rather look for variables that do.